BRMData: A Bimanual-Mobile Robot Manipulation Dataset for Household Tasks
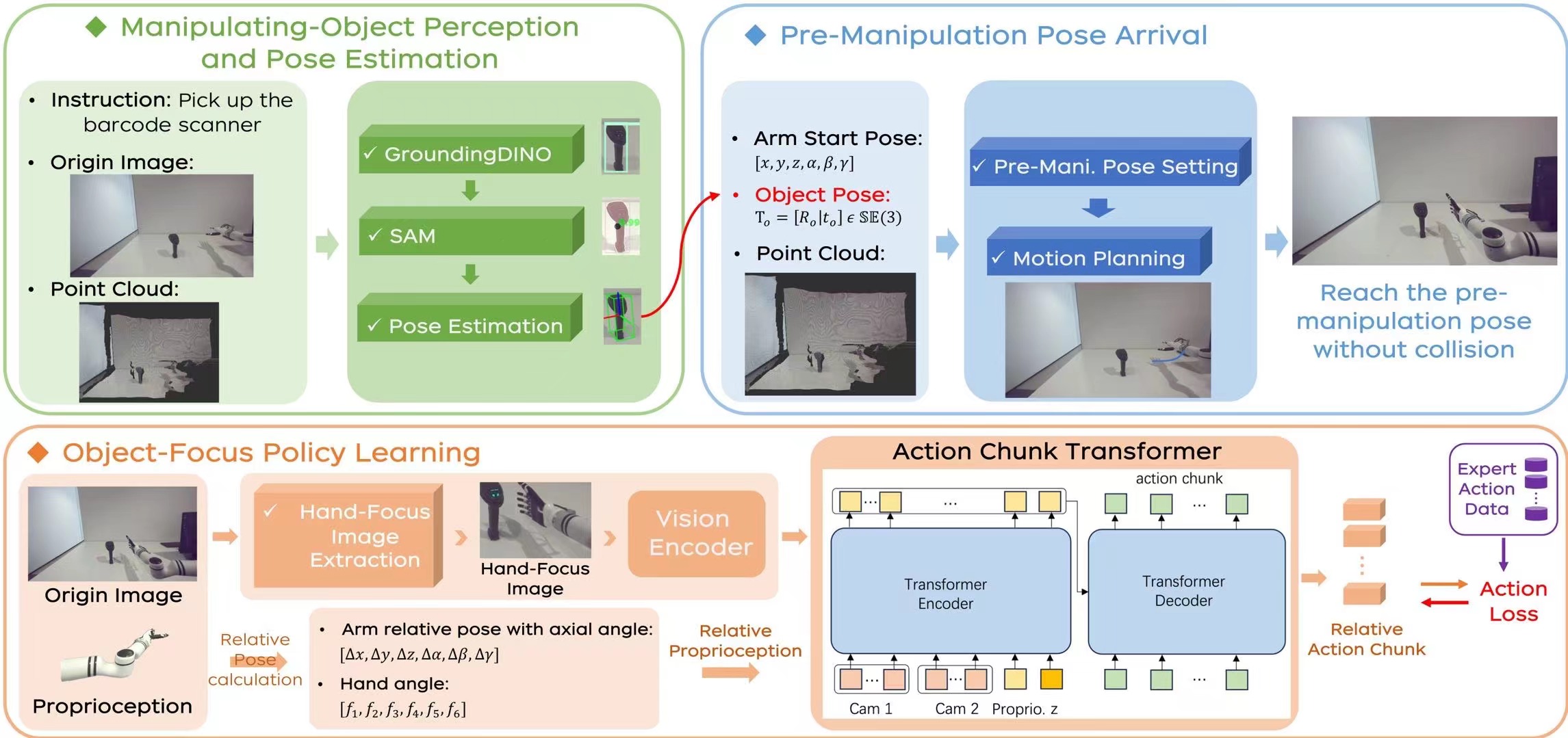
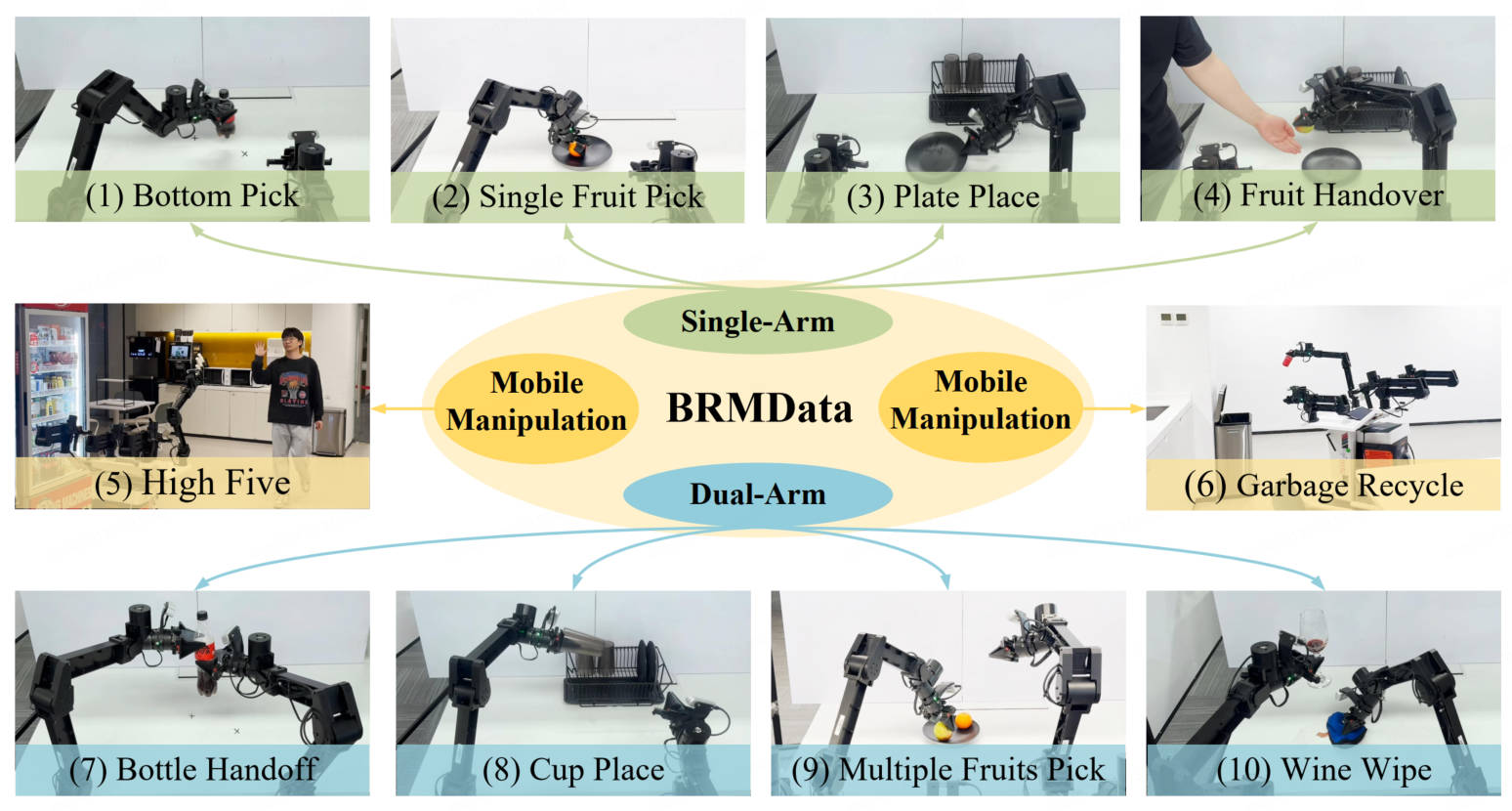
BRMData is a Bimanual-mobile Robot Manipulation Dataset designed for household applications, featuring 10 diverse tasks including single-arm and dual-arm, tabletop, and mobile manipulations. It includes multi-view and depth-sensing data, with tasks ranging from single-object to multi-object grasping, non-interactive to human-robot interactive scenarios, and rigid to flexible-object manipulation. A novel Manipulation Efficiency Score (MES) metric is introduced to evaluate the precision and efficiency of robot manipulation methods.